![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

pytorch-widedeep¶
A flexible package for multimodal-deep-learning to combine tabular data with text and images using Wide and Deep models in Pytorch
Documentation: https://pytorch-widedeep.readthedocs.io
Companion posts and tutorials: infinitoml
Experiments and comparison with LightGBM: TabularDL vs LightGBM
Slack: if you want to contribute or just want to chat with us, join slack
The content of this document is organized as follows:
Introduction¶
pytorch-widedeep is based on Google's Wide and Deep Algorithm,
adjusted for multi-modal datasets
In general terms, pytorch-widedeep is a package to use deep learning with
tabular data. In particular, is intended to facilitate the combination of text
and images with corresponding tabular data using wide and deep models. With
that in mind there are a number of architectures that can be implemented with
just a few lines of code. The main components of those architectures are shown
in the Figure below:
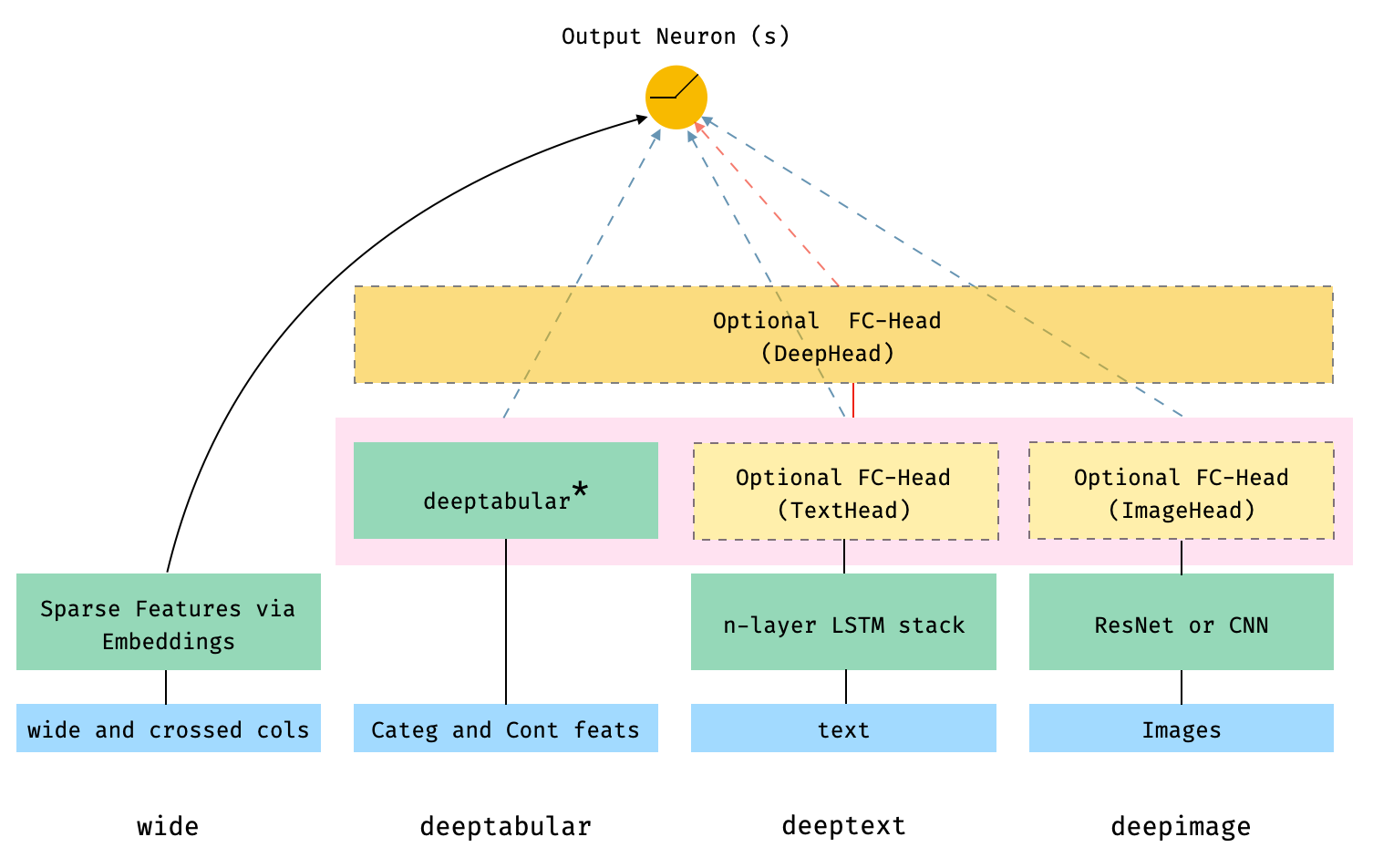
The dashed boxes in the figure represent optional, overall components, and the
dashed lines/arrows indicate the corresponding connections, depending on
whether or not certain components are present. For example, the dashed,
blue-lines indicate that the deeptabular, deeptext and deepimage
components are connected directly to the output neuron or neurons (depending
on whether we are performing a binary classification or regression, or a
multi-class classification) if the optional deephead is not present.
Finally, the components within the faded-pink rectangle are concatenated.
Note that it is not possible to illustrate the number of possible
architectures and components available in pytorch-widedeep in one Figure.
Therefore, for more details on possible architectures (and more) please, read
this documentation, or see the Examples folder in the repo.
In math terms, and following the notation in the
paper, the expression for the architecture
without a deephead component can be formulated as:
Where σ is the sigmoid function, 'W' are the weight matrices applied to the wide model and to the final activations of the deep models, 'a' are these final activations, φ(x) are the cross product transformations of the original features 'x', and , and 'b' is the bias term. In case you are wondering what are "cross product transformations", here is a quote taken directly from the paper: "For binary features, a cross-product transformation (e.g., “AND(gender=female, language=en)”) is 1 if and only if the constituent features (“gender=female” and “language=en”) are all 1, and 0 otherwise".
While if there is a deephead component, the previous expression turns
into:
It is perfectly possible to use custom models (and not necessarily those in
the library) as long as the the custom models have an attribute called
output_dim with the size of the last layer of activations, so that
WideDeep can be constructed. Examples on how to use custom components can
be found in the Examples folder.
The deeptabular component¶
It is important to emphasize that each individual component, wide,
deeptabular, deeptext and deepimage, can be used independently and in
isolation. For example, one could use only wide, which is in simply a
linear model. In fact, one of the most interesting functionalities
inpytorch-widedeep would be the use of the deeptabular component on
its own, i.e. what one might normally refer as Deep Learning for Tabular
Data. Currently, pytorch-widedeep offers the following different models
for that component:
- Wide: a simple linear model where the nonlinearities are captured via cross-product transformations, as explained before.
- TabMlp: a simple MLP that receives embeddings representing the categorical features, concatenated with the continuous features, which can also be embedded.
- TabResnet: similar to the previous model but the embeddings are passed through a series of ResNet blocks built with dense layers.
- TabNet: details on TabNet can be found in TabNet: Attentive Interpretable Tabular Learning
Two simpler attention based models that we call:
- ContextAttentionMLP: MLP with at attention mechanism "on top" that is based on Hierarchical Attention Networks for Document Classification
- SelfAttentionMLP: MLP with an attention mechanism that is a simplified version of a transformer block that we refer as "query-key self-attention".
The Tabformer family, i.e. Transformers for Tabular data:
- TabTransformer: details on the TabTransformer can be found in
TabTransformer: Tabular Data Modeling Using Contextual Embeddings.
Note that this is an 'enhanced' implementation that allows for many options that can be set up via
the
TabTransformerparams. - SAINT: Details on SAINT can be found in SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training.
- FT-Transformer: details on the FT-Transformer can be found in Revisiting Deep Learning Models for Tabular Data.
- TabFastFormer: adaptation of the FastFormer for tabular data. Details on the Fasformer can be found in FastFormers: Highly Efficient Transformer Models for Natural Language Understanding
- TabPerceiver: adaptation of the Perceiver for tabular data. Details on the Perceiver can be found in Perceiver: General Perception with Iterative Attention
And probabilistic DL models for tabular data based on Weight Uncertainty in Neural Networks:
- BayesianWide: Probabilistic adaptation of the
Widemodel. - BayesianTabMlp: Probabilistic adaptation of the
TabMlpmodel
Note that while there are scientific publications for the TabTransformer, SAINT and FT-Transformer, the TabFasfFormer and TabPerceiver are our own adaptation of those algorithms for tabular data.
In addition, Self-Supervised pre-training can be used for all deeptabular
models, with the exception of the TabPerceiver. Self-Supervised
pre-training can be used via two methods or routines which we refer as:
encoder-decoder method and constrastive-denoising method. Please, see the
documentation and the examples for details on this functionality, and all
other options in the library.
Acknowledgments¶
This library takes from a series of other libraries, so I think it is just fair to mention them here in the README (specific mentions are also included in the code).
The Callbacks and Initializers structure and code is inspired by the
torchsample library, which in
itself partially inspired by Keras.
The TextProcessor class in this library uses the
fastai's
Tokenizer and Vocab. The code at utils.fastai_transforms is a minor
adaptation of their code so it functions within this library. To my experience
their Tokenizer is the best in class.
The ImageProcessor class in this library uses code from the fantastic Deep
Learning for Computer
Vision
(DL4CV) book by Adrian Rosebrock.
License¶
This work is dual-licensed under Apache 2.0 and MIT (or any later version). You can choose between one of them if you use this work.
SPDX-License-Identifier: Apache-2.0 AND MIT
Cite¶
BibTex¶
@article{Zaurin_pytorch-widedeep_A_flexible_2023,
author = {Zaurin, Javier Rodriguez and Mulinka, Pavol},
doi = {10.21105/joss.05027},
journal = {Journal of Open Source Software},
month = jun,
number = {86},
pages = {5027},
title = {{pytorch-widedeep: A flexible package for multimodal deep learning}},
url = {https://joss.theoj.org/papers/10.21105/joss.05027},
volume = {8},
year = {2023}
}
APA¶
Zaurin, J. R., & Mulinka, P. (2023). pytorch-widedeep: A flexible package for
multimodal deep learning. Journal of Open Source Software, 8(86), 5027.
https://doi.org/10.21105/joss.05027