The FineTune/Warm Up option¶
Let's place ourselves in two possible scenarios.
Let's assume we have run a model and we want to just transfer the learnings (you know...transfer-learning) to another dataset, or simply we have received new data and we do not want to start the training of each component from scratch. Simply, we want to load the pre-trained weights and fine-tune.
We just want to "warm up" individual model components individually before the joined training begins.
This can be done with the finetune set of parameters. There are 3 fine-tuning routines:
- Fine-tune all trainable layers at once with a triangular one-cycle learning rate (referred as slanted triangular learning rates in Howard & Ruder 2018)
- Gradual fine-tuning inspired by the work of Felbo et al., 2017
- Gradual fine-tuning based on the work of Howard & Ruder 2018
Currently fine-tunning is only supported without a fully connected head, i.e. if deephead=None. In addition, Felbo and Howard routines only applied, of course, to the deeptabular, deeptext and deepimage models. The wide component can also be fine-tuned, but only in an "all at once" mode.
Fine-tune or warm-up all at once¶
Here, the model components will be trained for finetune_epochs using a triangular one-cycle learning rate (slanted triangular learning rate) ranging from finetune_max_lr/10 to finetune_max_lr (default is 0.01). 10% of the training steps are used to increase the learning rate which then decreases for the remaining 90%.
Here all trainable layers are fine-tuned.
Let's have a look to one example.
import numpy as np
import pandas as pd
import torch
from pytorch_widedeep import Trainer
from pytorch_widedeep.preprocessing import WidePreprocessor, TabPreprocessor
from pytorch_widedeep.models import Wide, TabMlp, TabResnet, WideDeep
from pytorch_widedeep.metrics import Accuracy
from pytorch_widedeep.datasets import load_adult
/Users/javierrodriguezzaurin/.pyenv/versions/3.10.13/envs/widedeep310/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
df = load_adult(as_frame=True)
# For convenience, we'll replace '-' with '_'
df.columns = [c.replace("-", "_") for c in df.columns]
# binary target
df["income_label"] = (df["income"].apply(lambda x: ">50K" in x)).astype(int)
df.drop("income", axis=1, inplace=True)
df.head()
| age | workclass | fnlwgt | education | educational_num | marital_status | occupation | relationship | race | gender | capital_gain | capital_loss | hours_per_week | native_country | income_label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 25 | Private | 226802 | 11th | 7 | Never-married | Machine-op-inspct | Own-child | Black | Male | 0 | 0 | 40 | United-States | 0 |
| 1 | 38 | Private | 89814 | HS-grad | 9 | Married-civ-spouse | Farming-fishing | Husband | White | Male | 0 | 0 | 50 | United-States | 0 |
| 2 | 28 | Local-gov | 336951 | Assoc-acdm | 12 | Married-civ-spouse | Protective-serv | Husband | White | Male | 0 | 0 | 40 | United-States | 1 |
| 3 | 44 | Private | 160323 | Some-college | 10 | Married-civ-spouse | Machine-op-inspct | Husband | Black | Male | 7688 | 0 | 40 | United-States | 1 |
| 4 | 18 | ? | 103497 | Some-college | 10 | Never-married | ? | Own-child | White | Female | 0 | 0 | 30 | United-States | 0 |
# Define wide, crossed and deep tabular columns
wide_cols = [
"workclass",
"education",
"marital_status",
"occupation",
"relationship",
"race",
"gender",
"native_country",
]
crossed_cols = [("education", "occupation"), ("native_country", "occupation")]
cat_embed_cols = [
"workclass",
"education",
"marital_status",
"occupation",
"relationship",
"race",
"gender",
"capital_gain",
"capital_loss",
"native_country",
]
continuous_cols = ["age", "hours_per_week"]
target_col = "income_label"
target = df[target_col].values
# TARGET
target = df[target_col].values
# WIDE
wide_preprocessor = WidePreprocessor(wide_cols=wide_cols, crossed_cols=crossed_cols)
X_wide = wide_preprocessor.fit_transform(df)
# DEEP
tab_preprocessor = TabPreprocessor(
cat_embed_cols=cat_embed_cols, continuous_cols=continuous_cols
)
X_tab = tab_preprocessor.fit_transform(df)
/Users/javierrodriguezzaurin/Projects/pytorch-widedeep/pytorch_widedeep/preprocessing/tab_preprocessor.py:358: UserWarning: Continuous columns will not be normalised
warnings.warn("Continuous columns will not be normalised")
wide = Wide(input_dim=np.unique(X_wide).shape[0], pred_dim=1)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
cat_embed_dropout=0.1,
continuous_cols=continuous_cols,
embed_continuous_method="standard",
cont_embed_dim=8,
mlp_hidden_dims=[64, 32],
mlp_dropout=0.2,
mlp_activation="leaky_relu",
)
model = WideDeep(wide=wide, deeptabular=tab_mlp)
trainer = Trainer(
model,
objective="binary",
optimizers=torch.optim.Adam(model.parameters(), lr=0.01),
metrics=[Accuracy],
)
trainer.fit(
X_wide=X_wide, X_tab=X_tab, target=target, n_epochs=2, val_split=0.2, batch_size=256
)
epoch 1: 100%|██████████████████████████████████████████████████████████| 153/153 [00:02<00:00, 74.26it/s, loss=0.399, metrics={'acc': 0.8163}]
valid: 100%|██████████████████████████████████████████████████████████████| 39/39 [00:00<00:00, 91.03it/s, loss=0.296, metrics={'acc': 0.8677}]
epoch 2: 100%|████████████████████████████████████████████████████████████| 153/153 [00:01<00:00, 81.31it/s, loss=0.3, metrics={'acc': 0.8614}]
valid: 100%|█████████████████████████████████████████████████████████████| 39/39 [00:00<00:00, 106.45it/s, loss=0.285, metrics={'acc': 0.8721}]
trainer.save(path="models_dir/", save_state_dict=True, model_filename="model_1.pt")
Now time goes by...and we want to fine-tune the model to another, new dataset (for example, a dataset that is identical to the one you used to train the previous model but for another country).
Here I will use the same dataset just for illustration purposes, but the flow would be identical to that new dataset
wide_1 = Wide(input_dim=np.unique(X_wide).shape[0], pred_dim=1)
tab_mlp_1 = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
cat_embed_dropout=0.1,
continuous_cols=continuous_cols,
embed_continuous_method="standard",
cont_embed_dim=8,
mlp_hidden_dims=[64, 32],
mlp_dropout=0.2,
mlp_activation="leaky_relu",
)
model_1 = WideDeep(wide=wide, deeptabular=tab_mlp)
model_1.load_state_dict(torch.load("models_dir/model_1.pt"))
<All keys matched successfully>
trainer_1 = Trainer(model_1, objective="binary", metrics=[Accuracy])
trainer_1.fit(
X_wide=X_wide,
X_tab=X_tab,
target=target,
n_epochs=2,
batch_size=256,
finetune=True,
finetune_epochs=2,
)
Training wide for 2 epochs
epoch 1: 100%|███████████████████████████████████████████████████████████| 191/191 [00:01<00:00, 97.37it/s, loss=0.39, metrics={'acc': 0.8152}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 191/191 [00:01<00:00, 104.04it/s, loss=0.359, metrics={'acc': 0.824}]
Training deeptabular for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 191/191 [00:02<00:00, 83.83it/s, loss=0.297, metrics={'acc': 0.8365}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 191/191 [00:02<00:00, 82.78it/s, loss=0.283, metrics={'acc': 0.8445}]
Fine-tuning (or warmup) of individual components completed. Training the whole model for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 191/191 [00:02<00:00, 72.84it/s, loss=0.281, metrics={'acc': 0.8716}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 191/191 [00:02<00:00, 77.46it/s, loss=0.273, metrics={'acc': 0.8744}]
Note that, as I describe above, in scenario 2, we can just use this to warm up models before they joined training begins:
wide = Wide(input_dim=np.unique(X_wide).shape[0], pred_dim=1)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
cat_embed_dropout=0.1,
continuous_cols=continuous_cols,
embed_continuous_method="standard",
cont_embed_dim=8,
mlp_hidden_dims=[64, 32],
mlp_dropout=0.2,
mlp_activation="leaky_relu",
)
model = WideDeep(wide=wide, deeptabular=tab_mlp)
trainer_2 = Trainer(model, objective="binary", metrics=[Accuracy])
trainer_2.fit(
X_wide=X_wide,
X_tab=X_tab,
target=target,
val_split=0.1,
warmup=True,
warmup_epochs=2,
n_epochs=2,
batch_size=256,
)
Training wide for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:01<00:00, 102.49it/s, loss=0.52, metrics={'acc': 0.7519}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 172/172 [00:01<00:00, 98.15it/s, loss=0.381, metrics={'acc': 0.7891}]
Training deeptabular for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 82.97it/s, loss=0.356, metrics={'acc': 0.8043}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 80.27it/s, loss=0.295, metrics={'acc': 0.8195}]
Fine-tuning (or warmup) of individual components completed. Training the whole model for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 77.27it/s, loss=0.291, metrics={'acc': 0.8667}]
valid: 100%|██████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 89.57it/s, loss=0.289, metrics={'acc': 0.8665}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 72.69it/s, loss=0.283, metrics={'acc': 0.8693}]
valid: 100%|███████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 91.81it/s, loss=0.284, metrics={'acc': 0.869}]
Fine-tune Gradually: The "felbo" and the "howard" routines¶
The Felbo routine can be illustrated as follows:
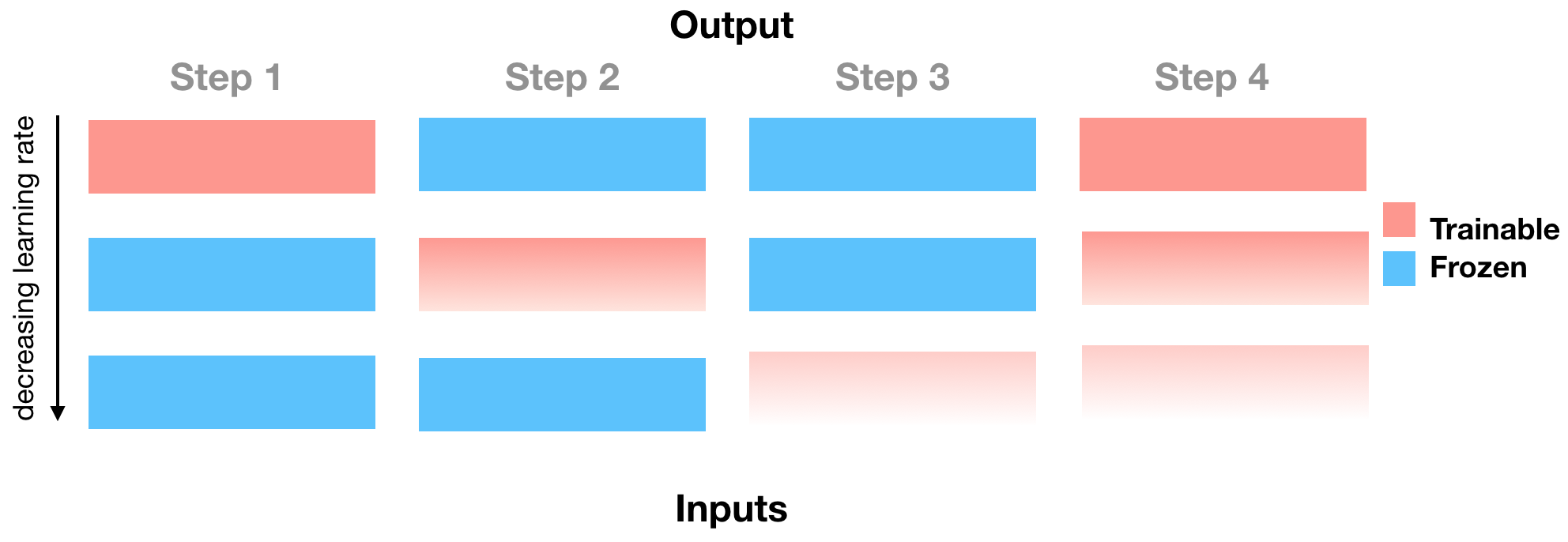
Figure 1. The figure can be described as follows: fine-tune (or train) the last layer for one epoch using a one cycle triangular learning rate. Then fine-tune the next deeper layer for one epoch, with a learning rate that is a factor of 2.5 lower than the previous learning rate (the 2.5 factor is fixed) while freezing the already warmed up layer(s). Repeat untill all individual layers are warmed. Then warm one last epoch with all warmed layers trainable. The vanishing color gradient in the figure attempts to illustrate the decreasing learning rate.
Note that this is not identical to the Fine-Tunning routine described in Felbo et al, 2017, this is why I used the word 'inspired'.
The Howard routine can be illustrated as follows:
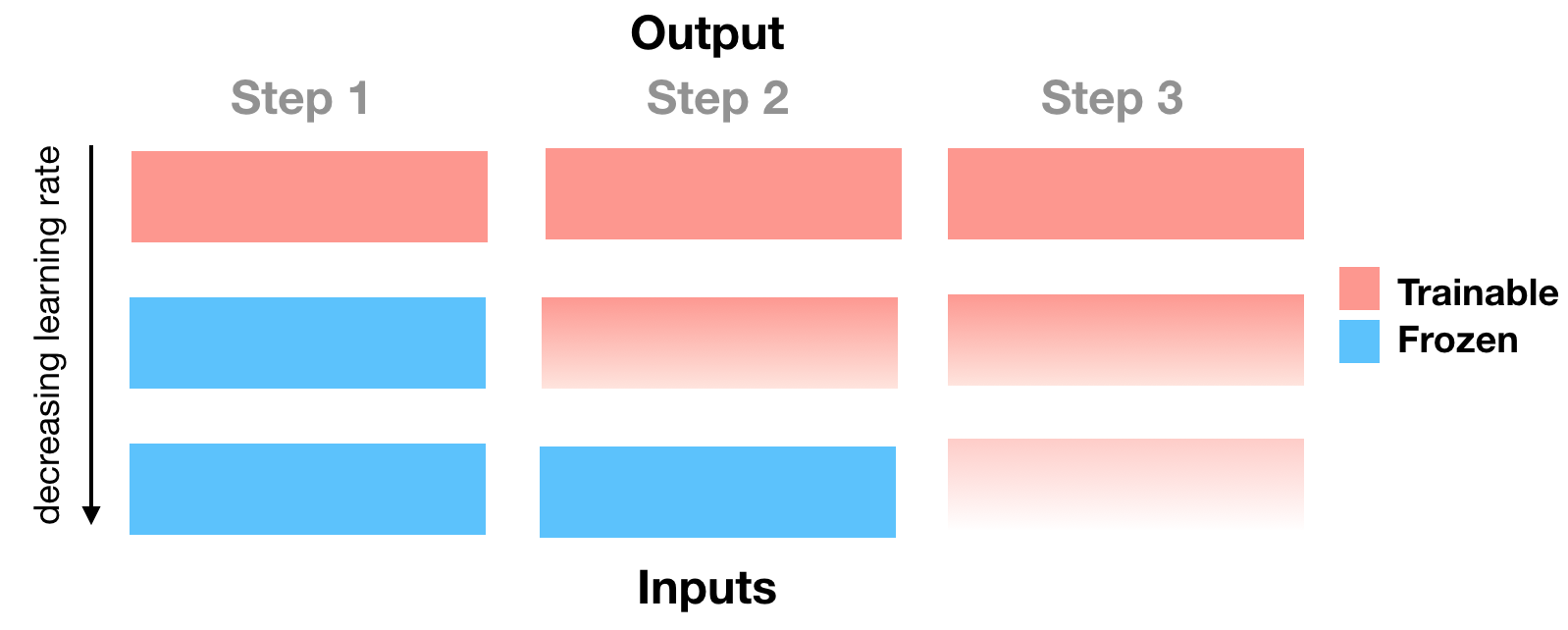
Figure 2. The figure can be described as follows: fine-tune (or train) the last layer for one epoch using a one cycle triangular learning rate. Then fine-tune the next deeper layer for one epoch, with a learning rate that is a factor of 2.5 lower than the previous learning rate (the 2.5 factor is fixed) while keeping the already warmed up layer(s) trainable. Repeat. The vanishing color gradient in the figure attempts to illustrate the decreasing learning rate.
Note that I write "fine-tune (or train) the last layer for one epoch [...]". However, in practice the user will have to specify the order of the layers to be fine-tuned. This is another reason why I wrote that the fine-tune routines I have implemented are inspired by the work of Felbo and Howard and not identical to their implemenations.
The felbo and howard routines can be accessed with via the fine-tune parameters.
We need to explicitly indicate
That we want fine-tune
The components that we want to individually fine-tune
In case of gradual fine-tuning, the routine ("felbo" or "howard")
The layers we want to fine-tune.
For example
wide = Wide(input_dim=np.unique(X_wide).shape[0], pred_dim=1)
tab_resnet = TabResnet(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
cat_embed_dropout=0.1,
continuous_cols=continuous_cols,
blocks_dims=[200, 200, 200],
)
model = WideDeep(wide=wide, deeptabular=tab_resnet)
model
WideDeep(
(wide): Wide(
(wide_linear): Embedding(809, 1, padding_idx=0)
)
(deeptabular): Sequential(
(0): TabResnet(
(cat_embed): DiffSizeCatEmbeddings(
(embed_layers): ModuleDict(
(emb_layer_workclass): Embedding(10, 5, padding_idx=0)
(emb_layer_education): Embedding(17, 8, padding_idx=0)
(emb_layer_marital_status): Embedding(8, 5, padding_idx=0)
(emb_layer_occupation): Embedding(16, 7, padding_idx=0)
(emb_layer_relationship): Embedding(7, 4, padding_idx=0)
(emb_layer_race): Embedding(6, 4, padding_idx=0)
(emb_layer_gender): Embedding(3, 2, padding_idx=0)
(emb_layer_capital_gain): Embedding(124, 24, padding_idx=0)
(emb_layer_capital_loss): Embedding(100, 21, padding_idx=0)
(emb_layer_native_country): Embedding(43, 13, padding_idx=0)
)
(embedding_dropout): Dropout(p=0.1, inplace=False)
)
(cont_norm): Identity()
(encoder): DenseResnet(
(dense_resnet): Sequential(
(lin_inp): Linear(in_features=95, out_features=200, bias=False)
(bn_inp): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(block_0): BasicBlock(
(lin1): Linear(in_features=200, out_features=200, bias=False)
(bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True)
(dp): Dropout(p=0.1, inplace=False)
(lin2): Linear(in_features=200, out_features=200, bias=False)
(bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(block_1): BasicBlock(
(lin1): Linear(in_features=200, out_features=200, bias=False)
(bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True)
(dp): Dropout(p=0.1, inplace=False)
(lin2): Linear(in_features=200, out_features=200, bias=False)
(bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
)
(1): Linear(in_features=200, out_features=1, bias=True)
)
)
let's first train as usual
trainer_3 = Trainer(model, objective="binary", metrics=[Accuracy])
trainer_3.fit(
X_wide=X_wide, X_tab=X_tab, target=target, val_split=0.1, n_epochs=2, batch_size=256
)
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:03<00:00, 54.23it/s, loss=0.382, metrics={'acc': 0.8239}]
valid: 100%|██████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 84.72it/s, loss=0.331, metrics={'acc': 0.8526}]
epoch 2: 100%|███████████████████████████████████████████████████████████| 172/172 [00:03<00:00, 54.35it/s, loss=0.33, metrics={'acc': 0.8465}]
valid: 100%|██████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 68.15it/s, loss=0.312, metrics={'acc': 0.8604}]
trainer_3.save(path="models_dir", save_state_dict=True, model_filename="model_3.pt")
Now we are going to fine-tune the model components, and in the case of the deeptabular component, we will fine-tune the resnet-blocks and the linear layer but NOT the embeddings.
For this, we need to access the model component's children: deeptabular $\rightarrow$ tab_resnet $\rightarrow$ dense_resnet $\rightarrow$ blocks
wide_3 = Wide(input_dim=np.unique(X_wide).shape[0], pred_dim=1)
tab_resnet_3 = TabResnet(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
cat_embed_dropout=0.1,
continuous_cols=continuous_cols,
blocks_dims=[200, 200, 200],
)
model_3 = WideDeep(wide=wide, deeptabular=tab_resnet)
model_3.load_state_dict(torch.load("models_dir/model_3.pt"))
<All keys matched successfully>
model_3
WideDeep(
(wide): Wide(
(wide_linear): Embedding(809, 1, padding_idx=0)
)
(deeptabular): Sequential(
(0): TabResnet(
(cat_embed): DiffSizeCatEmbeddings(
(embed_layers): ModuleDict(
(emb_layer_workclass): Embedding(10, 5, padding_idx=0)
(emb_layer_education): Embedding(17, 8, padding_idx=0)
(emb_layer_marital_status): Embedding(8, 5, padding_idx=0)
(emb_layer_occupation): Embedding(16, 7, padding_idx=0)
(emb_layer_relationship): Embedding(7, 4, padding_idx=0)
(emb_layer_race): Embedding(6, 4, padding_idx=0)
(emb_layer_gender): Embedding(3, 2, padding_idx=0)
(emb_layer_capital_gain): Embedding(124, 24, padding_idx=0)
(emb_layer_capital_loss): Embedding(100, 21, padding_idx=0)
(emb_layer_native_country): Embedding(43, 13, padding_idx=0)
)
(embedding_dropout): Dropout(p=0.1, inplace=False)
)
(cont_norm): Identity()
(encoder): DenseResnet(
(dense_resnet): Sequential(
(lin_inp): Linear(in_features=95, out_features=200, bias=False)
(bn_inp): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(block_0): BasicBlock(
(lin1): Linear(in_features=200, out_features=200, bias=False)
(bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True)
(dp): Dropout(p=0.1, inplace=False)
(lin2): Linear(in_features=200, out_features=200, bias=False)
(bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(block_1): BasicBlock(
(lin1): Linear(in_features=200, out_features=200, bias=False)
(bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True)
(dp): Dropout(p=0.1, inplace=False)
(lin2): Linear(in_features=200, out_features=200, bias=False)
(bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
)
(1): Linear(in_features=200, out_features=1, bias=True)
)
)
tab_lin_layer = list(model_3.deeptabular.children())[1]
tab_lin_layer
Linear(in_features=200, out_features=1, bias=True)
tab_deep_layers = []
for n1, c1 in model_3.deeptabular.named_children():
if (
n1 == "0"
): # 0 is the model component and 1 is always the prediction layer added by the `WideDeep` class
for n2, c2 in c1.named_children():
if n2 == "encoder": # TabResnet
for _, c3 in c2.named_children():
for n4, c4 in c3.named_children(): # dense_resnet
if "block" in n4:
tab_deep_layers.append((n4, c4))
tab_deep_layers
[('block_0',
BasicBlock(
(lin1): Linear(in_features=200, out_features=200, bias=False)
(bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True)
(dp): Dropout(p=0.1, inplace=False)
(lin2): Linear(in_features=200, out_features=200, bias=False)
(bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)),
('block_1',
BasicBlock(
(lin1): Linear(in_features=200, out_features=200, bias=False)
(bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True)
(dp): Dropout(p=0.1, inplace=False)
(lin2): Linear(in_features=200, out_features=200, bias=False)
(bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
))]
Now remember, we need to pass ONLY LAYERS (before I included the name for clarity) the layers in WARM UP ORDER, therefore:
tab_deep_layers = [el[1] for el in tab_deep_layers][::-1]
tab_layers = [tab_lin_layer] + tab_deep_layers[::-1]
tab_layers
[Linear(in_features=200, out_features=1, bias=True), BasicBlock( (lin1): Linear(in_features=200, out_features=200, bias=False) (bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True) (dp): Dropout(p=0.1, inplace=False) (lin2): Linear(in_features=200, out_features=200, bias=False) (bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ), BasicBlock( (lin1): Linear(in_features=200, out_features=200, bias=False) (bn1): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (leaky_relu): LeakyReLU(negative_slope=0.01, inplace=True) (dp): Dropout(p=0.1, inplace=False) (lin2): Linear(in_features=200, out_features=200, bias=False) (bn2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) )]
And now simply
trainer_4 = Trainer(model_3, objective="binary", metrics=[Accuracy])
trainer_4.fit(
X_wide=X_wide,
X_tab=X_tab,
target=target,
val_split=0.1,
finetune=True,
finetune_epochs=2,
deeptabular_gradual=True,
deeptabular_layers=tab_layers,
deeptabular_max_lr=0.01,
n_epochs=2,
batch_size=256,
)
Training wide for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:01<00:00, 95.17it/s, loss=0.504, metrics={'acc': 0.7523}]
epoch 2: 100%|███████████████████████████████████████████████████████████| 172/172 [00:01<00:00, 99.83it/s, loss=0.384, metrics={'acc': 0.789}]
Training deeptabular, layer 1 of 3
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 72.31it/s, loss=0.317, metrics={'acc': 0.8098}]
Training deeptabular, layer 2 of 3
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 65.97it/s, loss=0.312, metrics={'acc': 0.8214}]
Training deeptabular, layer 3 of 3
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 63.92it/s, loss=0.306, metrics={'acc': 0.8284}]
Fine-tuning (or warmup) of individual components completed. Training the whole model for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:03<00:00, 57.26it/s, loss=0.292, metrics={'acc': 0.8664}]
valid: 100%|██████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 84.56it/s, loss=0.292, metrics={'acc': 0.8696}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 172/172 [00:03<00:00, 53.61it/s, loss=0.282, metrics={'acc': 0.8693}]
valid: 100%|██████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 80.59it/s, loss=0.289, metrics={'acc': 0.8719}]
Finally, there is one more use case I would like to consider. The case where we train only one component and we just want to fine-tune and stop the training afterwards, since there is no joined training. This is a simple as
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
cat_embed_dropout=0.1,
continuous_cols=continuous_cols,
mlp_hidden_dims=[64, 32],
mlp_dropout=0.2,
mlp_activation="leaky_relu",
)
model = WideDeep(deeptabular=tab_mlp)
trainer_5 = Trainer(
model,
objective="binary",
optimizers=torch.optim.Adam(model.parameters(), lr=0.01),
metrics=[Accuracy],
)
trainer_5.fit(
X_wide=X_wide, X_tab=X_tab, target=target, val_split=0.1, n_epochs=1, batch_size=256
)
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 73.69it/s, loss=0.365, metrics={'acc': 0.8331}]
valid: 100%|██████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 92.56it/s, loss=0.299, metrics={'acc': 0.8673}]
trainer_5.save(path="models_dir", save_state_dict=True, model_filename="model_5.pt")
tab_mlp_5 = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
cat_embed_dropout=0.1,
continuous_cols=continuous_cols,
mlp_hidden_dims=[64, 32],
mlp_dropout=0.2,
mlp_activation="leaky_relu",
)
model_5 = WideDeep(deeptabular=tab_mlp_5)
model_5.load_state_dict(torch.load("models_dir/model_5.pt"))
<All keys matched successfully>
...times go by...
trainer_6 = Trainer(
model_5,
objective="binary",
optimizers=torch.optim.Adam(model.parameters(), lr=0.01),
metrics=[Accuracy],
)
trainer_6.fit(
X_wide=X_wide,
X_tab=X_tab,
target=target,
val_split=0.1,
finetune=True,
finetune_epochs=2,
finetune_max_lr=0.01,
stop_after_finetuning=True,
batch_size=256,
)
Training deeptabular for 2 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 73.86it/s, loss=0.298, metrics={'acc': 0.8652}]
epoch 2: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 75.45it/s, loss=0.286, metrics={'acc': 0.8669}]
Fine-tuning (or warmup) of individual components completed. Training the whole model for 1 epochs
epoch 1: 100%|██████████████████████████████████████████████████████████| 172/172 [00:02<00:00, 76.29it/s, loss=0.282, metrics={'acc': 0.8698}]
valid: 100%|██████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 84.93it/s, loss=0.281, metrics={'acc': 0.8749}]
import shutil
shutil.rmtree("models_dir/")
shutil.rmtree("model_weights/")