Self Supervised Pre-training for tabular data¶
In this library we have implemented two methods or routines that allow the
user to use self-suerpvised pre-training for all tabular models in the library
with the exception of the TabPerceiver (this is a particular model and
self-supervised pre-training requires some adjustments that will be
implemented in future versions). Please see the examples folder in the repo
or the examples section in the docs for details on how to use self-supervised
pre-training with this library.
The two routines implemented are illustrated in the figures below. The first is from TabNet: Attentive Interpretable Tabular Learning. It is a 'standard' encoder-decoder architecture and and is designed here for models that do not use transformer-based architectures (or when the embeddings can all have different dimensions). The second is from SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training, it is based on Contrastive and Denoising learning and is designed for models that use transformer-based architectures (or when the embeddings all need to have the same dimension):
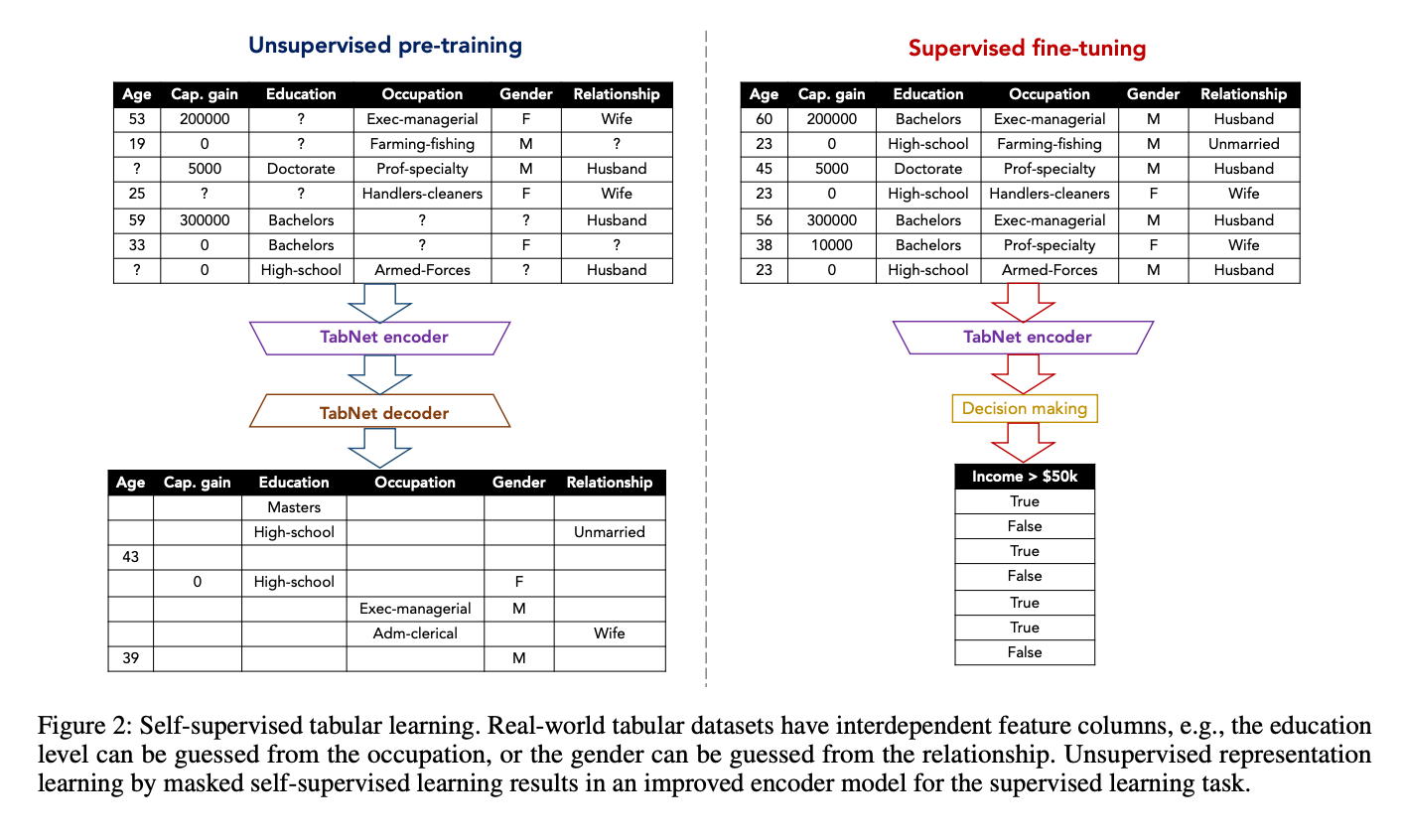
Figure 1. Figure 2 in their paper. The caption of the original paper is included in case it is useful.
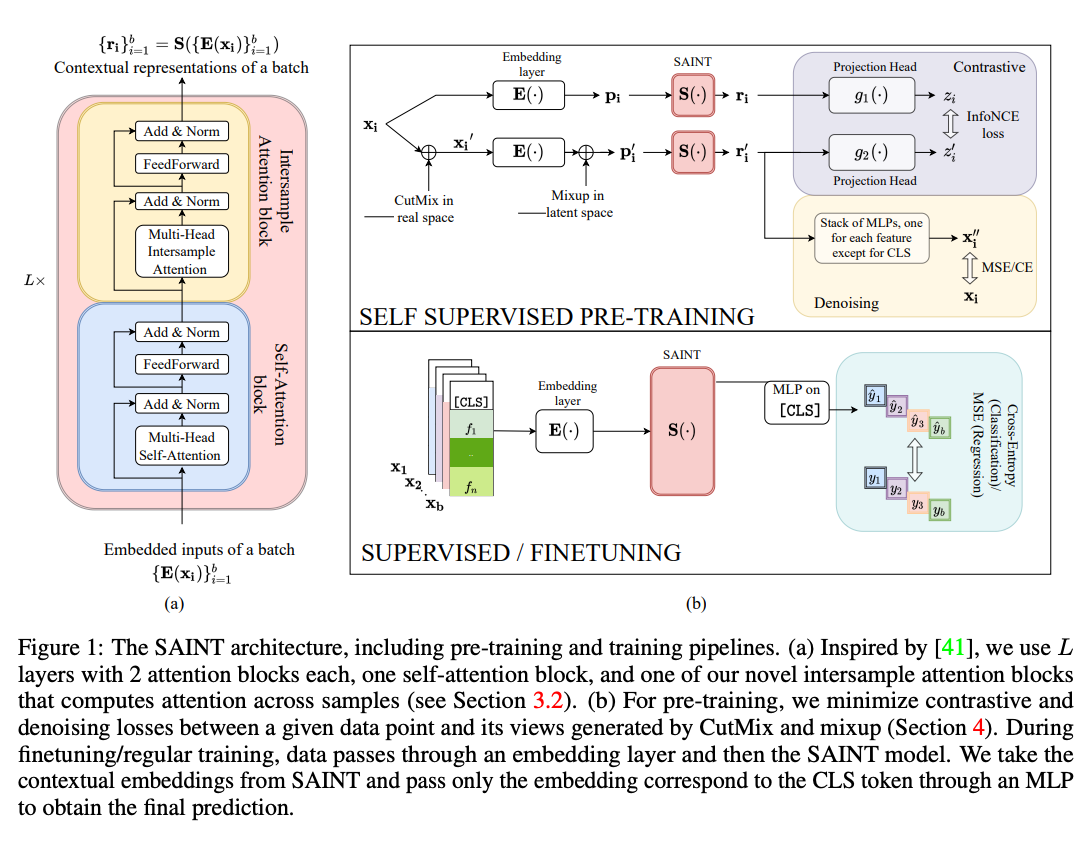
Figure 2. Figure 1 in their paper. The caption of the original paper is included in case it is useful.
Note that the self-supervised pre-trainers described below focus, of course,
on the self-supervised pre-training phase, i.e. the left side in Figure 1 and
the upper part in Figure 2. When combined with the Trainer described
earlier in the documenation, one can reproduce the full process illustrated
in the figures above.
Also Note that it is beyond the scope of this docs to explain in detail these routines. In addition, to fully utilise the self-supervised trainers implemented in this library a minimum understanding of the processes as described in the papers is required. Therefore, we strongly encourage the users to have a look to the papers.
EncoderDecoderTrainer ¶
EncoderDecoderTrainer(encoder, decoder=None, masked_prob=0.2, optimizer=None, lr_scheduler=None, callbacks=None, verbose=1, seed=1, **kwargs)
Bases: BaseEncoderDecoderTrainer
This class implements an Encoder-Decoder self-supervised 'routine' inspired by TabNet: Attentive Interpretable Tabular Learning. See Figure 1 above.
Parameters:
-
encoder(ModelWithoutAttention) –An instance of a
TabMlp,TabResNetorTabNetmodel -
decoder(Optional[DecoderWithoutAttention], default:None) –An instance of a
TabMlpDecoder,TabResNetDecoderorTabNetDecodermodel. ifNonethe decoder will be automatically built as a 'simetric' model to the Encoder -
masked_prob(float, default:0.2) –Indicates the fraction of elements in the embedding tensor that will be masked and hence used for reconstruction
-
optimizer(Optional[Optimizer], default:None) –An instance of Pytorch's
Optimizerobject (e.g.torch.optim.Adam ()). if no optimizer is passed it will default toAdamW. -
lr_scheduler(Optional[LRScheduler], default:None) –An instance of Pytorch's
LRSchedulerobject (e.gtorch.optim.lr_scheduler.StepLR(opt, step_size=5)). -
callbacks(Optional[List[Callback]], default:None) –List with
Callbackobjects. The three callbacks available inpytorch-widedeepare:LRHistory,ModelCheckpointandEarlyStopping. This can also be a custom callback. Seepytorch_widedeep.callbacks.Callbackor the Examples folder in the repo. -
verbose(int, default:1) –Setting it to 0 will print nothing during training.
-
seed(int, default:1) –Random seed to be used internally for train_test_split
Other Parameters:
-
**kwargs–Other infrequently used arguments that can also be passed as kwargs are:
-
device:
str
string indicating the device. One of 'cpu' or 'gpu' -
num_workers:
int
number of workers to be used internally by the data loaders -
reducelronplateau_criterion:
strThis sets the criterion that will be used by the lr scheduler to take a step: One of 'loss' or 'metric'. The ReduceLROnPlateau learning rate is a bit particular.
-
Source code in pytorch_widedeep/self_supervised_training/encoder_decoder_trainer.py
83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | |
pretrain ¶
pretrain(X_tab, X_tab_val=None, val_split=None, validation_freq=1, n_epochs=1, batch_size=32)
Pretrain method. Can also be called using .fit(<same_args>)
Parameters:
-
X_tab(ndarray) –tabular dataset
-
X_tab_val(Optional[ndarray], default:None) –validation data
-
val_split(Optional[float], default:None) –An alterative to passing the validation set is to use a train/val split fraction via
val_split -
validation_freq(int, default:1) –epochs validation frequency
-
n_epochs(int, default:1) –number of epochs
-
batch_size(int, default:32) –batch size
Source code in pytorch_widedeep/self_supervised_training/encoder_decoder_trainer.py
107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 | |
save ¶
save(path, save_state_dict=False, model_filename='ed_model.pt')
Saves the model, training and evaluation history (if any) to disk
Parameters:
-
path(str) –path to the directory where the model and the feature importance attribute will be saved.
-
save_state_dict(bool, default:False) –Boolean indicating whether to save directly the model or the model's state dictionary
-
model_filename(str, default:'ed_model.pt') –filename where the model weights will be store
Source code in pytorch_widedeep/self_supervised_training/encoder_decoder_trainer.py
214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 | |
ContrastiveDenoisingTrainer ¶
ContrastiveDenoisingTrainer(model, preprocessor, optimizer=None, lr_scheduler=None, callbacks=None, loss_type='both', projection_head1_dims=None, projection_head2_dims=None, projection_heads_activation='relu', cat_mlp_type='multiple', cont_mlp_type='multiple', denoise_mlps_activation='relu', verbose=1, seed=1, **kwargs)
Bases: BaseContrastiveDenoisingTrainer
This class trains a Contrastive, Denoising Self Supervised 'routine' that is based on the one described in SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training, their Figure 1.
Parameters:
-
model(ModelWithAttention) –An instance of a
TabTransformer,SAINT,FTTransformer,TabFastFormer,TabPerceiver,ContextAttentionMLPandSelfAttentionMLP. -
preprocessor(TabPreprocessor) –A fitted
TabPreprocessorobject. Seepytorch_widedeep.preprocessing.tab_preprocessor.TabPreprocessor -
optimizer(Optional[Optimizer], default:None) –An instance of Pytorch's
Optimizerobject (e.g.torch.optim.Adam ()). if no optimizer is passed it will default toAdamW. -
lr_scheduler(Optional[LRScheduler], default:None) –An instance of Pytorch's
LRSchedulerobject (e.gtorch.optim.lr_scheduler.StepLR(opt, step_size=5)). -
callbacks(Optional[List[Callback]], default:None) –List with
Callbackobjects. The three callbacks available inpytorch-widedeepare:LRHistory,ModelCheckpointandEarlyStopping. This can also be a custom callback. Seepytorch_widedeep.callbacks.Callbackor the Examples folder in the repo. -
loss_type(Literal[contrastive, denoising, both], default:'both') –One of 'contrastive', 'denoising' or 'both'. See SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training, their figure (1) and their equation (5).
-
projection_head1_dims(Optional[List[int]], default:None) –The projection heads are simply MLPs. This parameter is a list of integers with the dimensions of the MLP hidden layers. See the paper for details. Note that setting up this parameter requires some knowledge of the architecture one is using. For example, if we are representing the features with embeddings of dim 32 (i.e. the so called dimension of the model is 32), then the first dimension of the projection head must be 32 (e.g. [32, 16])
-
projection_head2_dims(Optional[List[int]], default:None) –Same as 'projection_head1_dims' for the second head
-
projection_heads_activation(str, default:'relu') –Activation function for the projection heads
-
cat_mlp_type(Literal[single, multiple], default:'multiple') –If 'denoising' loss is used, one can choose two types of 'stacked' MLPs to process the output from the transformer-based encoder that receives 'corrupted' (cut-mixed and mixed-up) features. These are 'single' or 'multiple'. The former approach will apply a single MLP to all the categorical features while the latter will use one MLP per categorical feature
-
cont_mlp_type(Literal[single, multiple], default:'multiple') –Same as 'cat_mlp_type' but for the continuous features
-
denoise_mlps_activation(str, default:'relu') –activation function for the so called 'denoising mlps'.
-
verbose(int, default:1) –Setting it to 0 will print nothing during training.
-
seed(int, default:1) –Random seed to be used internally for train_test_split
Other Parameters:
-
**kwargs–Other infrequently used arguments that can also be passed as kwargs are:
-
device:
str
string indicating the device. One of 'cpu' or 'gpu' -
num_workers:
int
number of workers to be used internally by the data loaders -
reducelronplateau_criterion:
strThis sets the criterion that will be used by the lr scheduler to take a step: One of 'loss' or 'metric'. The ReduceLROnPlateau learning rate is a bit particular.
-
Source code in pytorch_widedeep/self_supervised_training/contrastive_denoising_trainer.py
111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 | |
pretrain ¶
pretrain(X_tab, X_tab_val=None, val_split=None, validation_freq=1, n_epochs=1, batch_size=32)
Pretrain method. Can also be called using .fit(<same_args>)
Parameters:
-
X_tab(ndarray) –tabular dataset
-
X_tab_val(Optional[ndarray], default:None) –validation data. Note that, although it is possible to use contrastive-denoising training with a validation set, such set must include feature values that are all seen in the training set in the case of the categorical columns. This is because the values of the columns themselves will be used as targets when computing the loss. Therefore, if a new category is present in the validation set that was not seen in training this will effectively be like trying to predict a new, never seen category (and Pytorch will throw an error)
-
val_split(Optional[float], default:None) –An alterative to passing the validation set is to use a train/val split fraction via
val_split -
validation_freq(int, default:1) –epochs validation frequency
-
n_epochs(int, default:1) –number of epochs
-
batch_size(int, default:32) –batch size
Source code in pytorch_widedeep/self_supervised_training/contrastive_denoising_trainer.py
147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 | |
save ¶
save(path, save_state_dict=False, model_filename='cd_model.pt')
Saves the model, training and evaluation history (if any) to disk
Parameters:
-
path(str) –path to the directory where the model and the feature importance attribute will be saved.
-
save_state_dict(bool, default:False) –Boolean indicating whether to save directly the model or the model's state dictionary
-
model_filename(str, default:'cd_model.pt') –filename where the model weights will be store
Source code in pytorch_widedeep/self_supervised_training/contrastive_denoising_trainer.py
262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 | |